Unlock the power of offline speech recognition with the VOSK API!
Published:
TL;DR
Vosk API Overview: A powerful, offline speech recognition framework for converting spoken language into text without needing an internet connection.
I’m excited to share more about my journey with Automated Speech Recognition! Today, I’m diving into the Vosk API, an exceptional plug-and-play library that truly captivates me. As I mentioned in my previous posts, I successfully developed a speech model from scratch using the Kaldi ASR toolkit, and I’m thrilled to see how Vosk effectively uses some of Kaldi’s practices!
What is Vosk API?
Vosk is an innovative framework for offline speech recognition that empowers users to seamlessly convert spoken language into text without needing an internet connection. It’s a game-changer for those who want reliable and efficient voice processing on the go! Vosk seamlessly integrates with wearables, mobile apps, IoT, and edge devices. Facilitates Speaker Recognition
Which languages will Vosk support?
Vosk supports 20+ languages and dialects - English, Indian English, German, French, Spanish, Portuguese, Chinese, Russian, Turkish, Vietnamese, Italian, Dutch, Catalan, Arabic, Greek, Farsi, Filipino, Ukrainian, Kazakh, Swedish, Japanese, Esperanto, Hindi, Czech, Polish, Uzbek, Korean, Breton, Gujarati, Tajik, Telugu. More to come.
When and Why You Should Use Vosk?
With my extensive experience, I confidently understand the complexities involved in training models, particularly in the area of speech recognition. The primary challenge in this process is obtaining high-quality data. However, the Vosk API provides a powerful solution, as its model has been trained on a considerable volume of speech data, ensuring outstanding accuracy.
The Vosk API is an excellent choice for any application requiring seamless integration with speech recognition. This includes chatbots, smart home devices, and virtual assistants. Additionally, it can efficiently generate subtitles for movies and provide accurate transcriptions for lectures and interviews.
The Vosk API library offers seamless integration capabilities with various programming languages, specifically Java, C#, and JavaScript.
Example Code:
prerequisite:
- Python 3.x.x installed
- a good quality audio file to test. Example audio file
import wave
import sys
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
from vosk import Model, KaldiRecognizer
wf = wave.open(sys.argv[1], "rb")
if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != "NONE":
sys.exit(1)
model = Model(lang="en-us")
asr_rec = KaldiRecognizer(model, wf.getframerate())
asr_rec.SetWords(True)
asr_rec.SetPartialWords(True)
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if asr_rec.AcceptWaveform(data):
print(asr_rec.Result())
else:
print(asr_rec.PartialResult())
print(asr_rec.FinalResult())
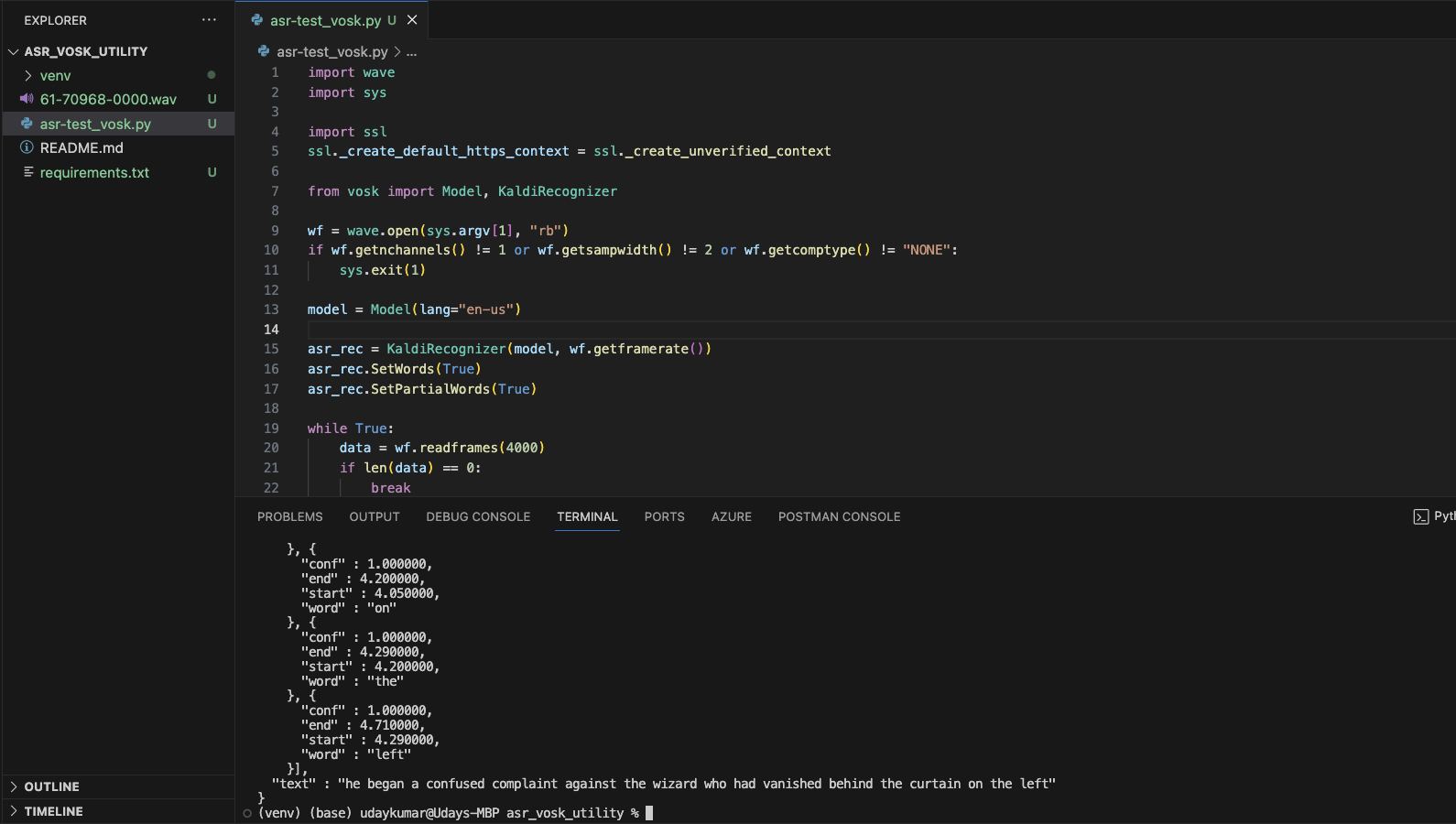
How to run?
python asr-test.py 61-70968-0000.wav
References are available at:
Conclusion Encouragement to explore Vosk API for various projects involving speech recognition. Kudos to Vosk api contributors
What’s Next?
I am currently exploring the capabilities of the Whisper API for voice-to-text conversion, which appears to demonstrate a high level of accuracy. I will provide additional information in due course.